一、COVID-19 案例
在前面的文章中,有使用 MapReduce 实践 COVID-19 新冠肺炎案例,本篇基于 Spark 对该数据集进行分析,下面是 MapReduce 案例的文章地址:
数据格式如下所示:
date(日期),county(县),state(州),fips(县编码code),cases(累计确诊病例),deaths(累计死亡病例)
2021-01-28,Pike,Alabama,01109,2704,35
2021-01-28,Randolph,Alabama,01111,1505,37
2021-01-28,Russell,Alabama,01113,3675,16
2021-01-28,Shelby,Alabama,01117,19878,141
2021-01-28,St. Clair,Alabama,01115,8047,147
2021-01-28,Sumter,Alabama,01119,925,28
2021-01-28,Talladega,Alabama,01121,6711,114
2021-01-28,Tallapoosa,Alabama,01123,3258,112
2021-01-28,Tuscaloosa,Alabama,01125,22083,283
2021-01-28,Walker,Alabama,01127,6105,185
2021-01-28,Washington,Alabama,01129,1454,27
数据集下载:
二、计算各个州的累积cases、deaths
思路:
- 读取数据集
- 转换键值对,
key:州,value:各个县的cases、deaths值 - 根据
key聚合,相加cases、deaths值 - 根据州排序输出
- Scala:
object CovidSum {
case class CovidVO(cases: Long, deaths: Long) extends java.io.Serializable
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("spark").setMaster("local[*]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val t1 = sc.textFile("D:/test/input/")
t1.filter(StringUtils.isNotBlank)
.map(s => {
val line = s.split(",")
if (line.size >= 6) {
val state = line(2)
val cases = line(4).toLong
val deaths = line(5).toLong
(state, CovidVO(cases, deaths))
} else {
null
}
}).filter(Objects.nonNull)
.reduceByKey((v1, v2) => CovidVO(v1.cases + v2.cases, v1.deaths + v2.deaths))
.sortByKey(ascending = true, 1)
.foreach(t => {
println(t._1 + " " + t._2.cases + " " + t._2.deaths)
})
}
}
- Java:
public class CvoidSum {
@Data
@AllArgsConstructor
@NoArgsConstructor
static class CovidVO implements Serializable {
private Long cases;
private Long deaths;
}
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("spark").setMaster("local[*]");
JavaSparkContext sc = new JavaSparkContext(conf);
sc.setLogLevel("WARN");
JavaRDD<String> t1 = sc.textFile("D:/test/input/");
t1.filter(StringUtils::isNotBlank)
.mapToPair(s -> {
List<String> line = Arrays.asList(s.split(","));
if (line.size() >= 6) {
String state = line.get(2);
Long cases = Long.parseLong(line.get(4));
Long deaths = Long.parseLong(line.get(5));
return new Tuple2<>(state, new CovidVO(cases, deaths));
}
return null;
}).filter(Objects::nonNull)
.reduceByKey((v1, v2) -> new CovidVO(v1.getCases() + v2.getCases(), v1.getDeaths() + v2.getDeaths()))
.sortByKey(true, 1)
.foreach(t -> {
System.out.println(t._1 + " " + t._2.getCases() + " " + t._2.getDeaths());
});
}
}
- Python:
from pyspark import SparkConf, SparkContext
import findspark
if __name__ == '__main__':
findspark.init()
conf = SparkConf().setAppName('spark').setMaster('local[*]')
sc = SparkContext(conf=conf)
sc.setLogLevel("WARN")
t1 = sc.textFile("D:/test/input/")
def mapT(s):
line = s.split(",")
if (len(line) >= 6):
state = line[2]
casesStr = line[4]
deathsStr = line[5]
cases = int(casesStr if (casesStr and casesStr != '') else '0')
deaths = int(deathsStr if (deathsStr and deathsStr != '') else '0')
return (state, (cases, deaths))
else:
return None
t1.filter(lambda s: s and s != '') \
.map(mapT) \
.filter(lambda s: s != None) \
.reduceByKey(lambda v1, v2: (v1[0] + v2[0], v1[1] + v2[1])) \
.sortByKey(ascending=True, numPartitions=1) \
.foreach(lambda t: print(t[0] + " " + str(t[1][0]) + " " + str(t[1][1])))
统计结果:
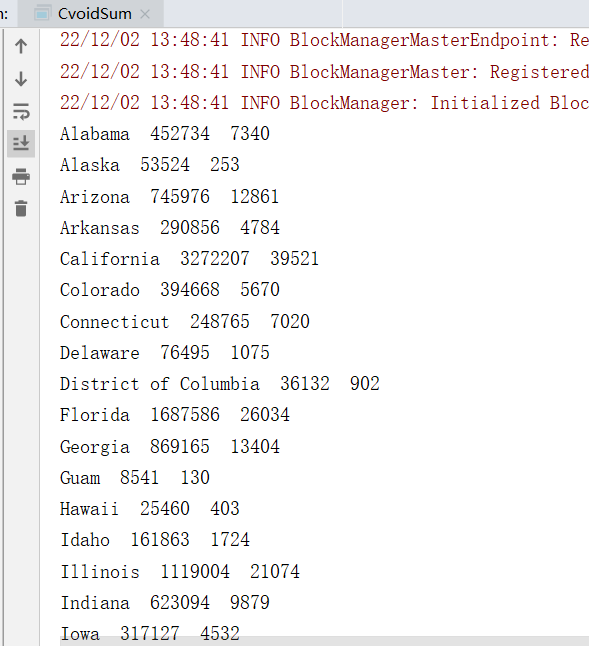
三、计算各个州的累积cases、deaths,并根据 deaths 降序排列
思路:
- 读取数据集
- 转换键值对,
key:州,value:各个县的cases、deaths值 - 根据
key聚合,相加cases、deaths值 - 根据
value中的deaths降序排列输出
- Scala:
object CovidSumSortDeaths {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("spark").setMaster("local[*]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val t1 = sc.textFile("D:/test/input/")
t1.filter(StringUtils.isNotBlank)
.map(s => {
val line = s.split(",")
if (line.size >= 6) {
val state = line(2)
val cases = line(4).toLong
val deaths = line(5).toLong
(state, CovidVO(cases, deaths))
} else {
null
}
}).filter(Objects.nonNull)
.reduceByKey((v1, v2) => CovidVO(v1.cases + v2.cases, v1.deaths + v2.deaths))
.sortBy(_._2.deaths, ascending = false, 1)
.foreach(t => {
println(t._1 + " " + t._2.cases + " " + t._2.deaths)
})
}
}
- Java:
public class CvoidSumSortDeaths {
@Data
@AllArgsConstructor
@NoArgsConstructor
static class CovidVO implements Serializable {
private Long cases;
private Long deaths;
}
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("spark").setMaster("local[*]");
JavaSparkContext sc = new JavaSparkContext(conf);
sc.setLogLevel("WARN");
JavaRDD<String> t1 = sc.textFile("D:/test/input/");
t1.filter(StringUtils::isNotBlank)
.mapToPair(s -> {
List<String> line = Arrays.asList(s.split(","));
if (line.size() >= 6) {
String state = line.get(2);
Long cases = Long.parseLong(line.get(4));
Long deaths = Long.parseLong(line.get(5));
return new Tuple2<>(state, new CovidVO(cases, deaths));
}
return null;
}).filter(Objects::nonNull)
.reduceByKey((v1, v2) -> new CovidVO(v1.getCases() + v2.getCases(), v1.getDeaths() + v2.getDeaths()))
.map(t -> new Tuple2<String, CovidVO>(t._1, t._2))
.sortBy(t -> t._2.getDeaths(), false, 1)
.foreach(t -> {
System.out.println(t._1 + " " + t._2.getCases() + " " + t._2.getDeaths());
});
}
}
- Python:
from pyspark import SparkConf, SparkContext
import findspark
if __name__ == '__main__':
findspark.init()
conf = SparkConf().setAppName('spark').setMaster('local[*]')
sc = SparkContext(conf=conf)
sc.setLogLevel("WARN")
t1 = sc.textFile("D:/test/input/")
def mapT(s):
line = s.split(",")
if (len(line) >= 6):
state = line[2]
casesStr = line[4]
deathsStr = line[5]
cases = int(casesStr if (casesStr and casesStr != '') else '0')
deaths = int(deathsStr if (deathsStr and deathsStr != '') else '0')
return (state, (cases, deaths))
else:
return None
t1.filter(lambda s: s and s != '') \
.map(mapT) \
.filter(lambda s: s != None) \
.reduceByKey(lambda v1, v2: (v1[0] + v2[0], v1[1] + v2[1])) \
.sortBy(lambda t: t[1][1], ascending=False, numPartitions=1) \
.foreach(lambda t: print(t[0] + " " + str(t[1][0]) + " " + str(t[1][1])))
统计结果:
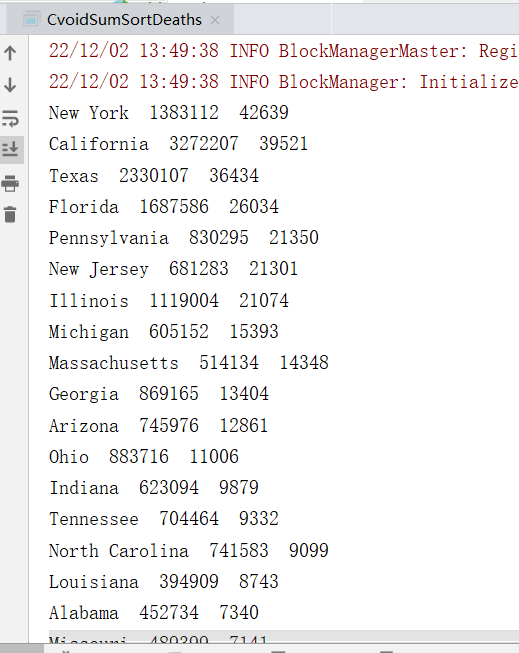
四、计算各个州根据 deaths 排列Top3的县
思路:
- 读取数据集
- 转换键值对,
key:州,value:各个 县 以及cases、deaths值 - 根据
key聚合,相加cases、deaths值 - 声明一个长度为
3的数组,来实时计算存储top3的值,从而减少全量排序的Shuffle占用内存过大问题 - 先计算出每个分区
top3的值 - 对各个分区
top3的值进行比较求取最终top3的值 - 根据州排序输出
- Scala:
object CovidTopDeaths {
case class CovidVO(county: String, cases: Long, deaths: Long) extends java.io.Serializable
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("spark").setMaster("local[*]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val t1 = sc.textFile("D:/test/input/")
t1.filter(StringUtils.isNotBlank)
.map(s => {
val line = s.split(",")
if (line.size >= 6) {
val state = line(2)
val county = line(1)
val cases = line(4).toLong
val deaths = line(5).toLong
(state, CovidVO(county, cases, deaths))
} else {
null
}
}).filter(Objects.nonNull)
.aggregateByKey(new Array[CovidVO](3))(
(zeroValue: Array[CovidVO], currentValue: CovidVO) => {
comparison(zeroValue, currentValue)
},
(topP1: Array[CovidVO], topP2: Array[CovidVO]) => {
var top = topP2
for (topP1Value <- topP1) {
top = comparison(top, topP1Value)
}
top
}
).sortByKey(ascending = true, 1)
.foreach(t => {
for (topValue <- t._2) {
if (Objects.nonNull(topValue)) println(t._1 + " " + topValue)
}
})
}
def comparison(topValue: Array[CovidVO], currentValue: CovidVO): Array[CovidVO] = {
var flag = true
for (i <- topValue.indices if flag) {
if (topValue(i) == null) {
topValue(i) = currentValue
flag = false
} else if (currentValue.deaths > topValue(i).deaths) {
for (j <- topValue.length - 1 to i + 1 by -1) {
topValue(j) = topValue(j - 1)
}
topValue(i) = currentValue
flag = false
}
}
topValue
}
}
- Java:
public class CvoidTopDeaths {
@Data
@AllArgsConstructor
@NoArgsConstructor
static class CovidVO implements Serializable {
private String county;
private Long cases;
private Long deaths;
}
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("spark").setMaster("local[*]");
JavaSparkContext sc = new JavaSparkContext(conf);
sc.setLogLevel("WARN");
JavaRDD<String> t1 = sc.textFile("D:/test/input/");
t1.filter(StringUtils::isNotBlank)
.mapToPair(s -> {
List<String> line = Arrays.asList(s.split(","));
if (line.size() >= 6) {
String state = line.get(2);
String county = line.get(1);
Long cases = Long.parseLong(line.get(4));
Long deaths = Long.parseLong(line.get(5));
return new Tuple2<>(state, new CovidVO(county, cases, deaths));
}
return null;
}).filter(Objects::nonNull)
.aggregateByKey(
new CovidVO[3],
CvoidTopDeaths::comparison,
(topP1, topP2) -> {
for (CovidVO topP1Value : topP1) {
topP2 = comparison(topP2, topP1Value);
}
return topP2;
})
.sortByKey(true, 1)
.foreach(t -> {
for (CovidVO topValue : t._2) {
if (Objects.nonNull(topValue)) {
System.out.println(t._1 + " " + topValue);
}
}
});
}
private static CovidVO[] comparison(CovidVO[] topValue, CovidVO currentValue) {
for (int i = 0; i < 3; i++) {
if (topValue[i] == null) {
topValue[i] = currentValue;
break;
} else if (currentValue.deaths > topValue[i].deaths) {
for (int j = topValue.length - 1; j > i; j--) {
topValue[j] = topValue[j - 1];
}
topValue[i] = currentValue;
break;
}
}
return topValue;
}
}
- Python:
from pyspark import SparkConf, SparkContext, StorageLevel
import findspark
if __name__ == '__main__':
findspark.init()
conf = SparkConf().setAppName('spark').setMaster('local[*]')
sc = SparkContext(conf=conf)
sc.setLogLevel("WARN")
t1 = sc.textFile("D:/test/input/")
def mapT(s):
line = s.split(",")
if (len(line) >= 6):
state = line[2]
county = line[1]
casesStr = line[4]
deathsStr = line[5]
cases = int(casesStr if (casesStr and casesStr != '') else '0')
deaths = int(deathsStr if (deathsStr and deathsStr != '') else '0')
return (state, (county, cases, deaths))
else:
return None
def comparison(topValue, currentValue):
for i in range(0, 3):
if topValue[i] == None:
topValue[i] = currentValue
break
elif currentValue[2] > topValue[i][2]:
for j in range(len(topValue) - 1, i, -1):
topValue[j] = topValue[j - 1]
topValue[i] = currentValue
break
return topValue
def comparison2(topP1, topP2):
for v in topP1:
topP2 = comparison(topP2, v)
return topP2
def printValue(top):
for t in top[1]:
if t: print(top[0], t[0], t[1], t[2])
t1.filter(lambda s: s and s != '') \
.map(mapT) \
.filter(lambda s: s != None) \
.aggregateByKey([None, None, None], comparison, comparison2) \
.sortByKey(True, 1) \
.foreach(printValue)
统计结果:

五、计算各个州 cases、deaths 的平均值,并根据 deaths 的平均值降序排列
思路:
- 读取数据集
- 转换键值对,
key:州,value:各个 县 以及cases、deaths值 - 根据
key聚合,相加cases、deaths值 - 声明初始值,
cases、deaths默认为0,再声明一个全局计数器默认为0 - 先计算出每个分区
cases、deaths的总和,以及计数。 - 对各个分区
cases、deaths的总和和计数进行相加 - 对相加后
cases、deaths / 计数的总和得到每个key的平均值 - 根据
value中的deaths降序排列输出
- Scala:
object CovidAvgSortDeaths {
case class CovidVO(cases: Double, deaths: Double) extends java.io.Serializable
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("spark").setMaster("local[*]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val t1 = sc.textFile("D:/test/input/")
t1.filter(StringUtils.isNotBlank)
.map(s => {
val line = s.split(",")
if (line.size >= 6) {
val state = line(2)
val cases = line(4).toDouble
val deaths = line(5).toDouble
(state, CovidVO(cases, deaths))
} else {
null
}
}).filter(Objects.nonNull)
.aggregateByKey((CovidVO(0D, 0D), 0))(
(zeroValue, currentValue) => {
(CovidVO(zeroValue._1.cases + currentValue.cases, zeroValue._1.deaths + currentValue.deaths), zeroValue._2 + 1)
},
(topP1, topP2) => {
(CovidVO(topP1._1.cases + topP2._1.cases, topP1._1.deaths + topP2._1.deaths), topP1._2 + topP2._2)
}
)
.map(t => (t._1, CovidVO(t._2._1.cases / t._2._2, t._2._1.deaths / t._2._2)))
.sortBy(t => t._2.deaths, ascending = false, 1)
.foreach(t => {
println(t._1 + " " + t._2)
})
}
}
- Java
public class CvoidAvgSortDeaths {
@Data
@AllArgsConstructor
@NoArgsConstructor
static class CovidVO implements Serializable {
private Double cases;
private Double deaths;
}
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("spark").setMaster("local[*]");
JavaSparkContext sc = new JavaSparkContext(conf);
sc.setLogLevel("WARN");
JavaRDD<String> t1 = sc.textFile("D:/test/input/");
t1.filter(StringUtils::isNotBlank)
.mapToPair(s -> {
List<String> line = Arrays.asList(s.split(","));
if (line.size() >= 6) {
String state = line.get(2);
Double cases = Double.parseDouble(line.get(4));
Double deaths = Double.parseDouble(line.get(5));
return new Tuple2<>(state, new CovidVO(cases, deaths));
}
return null;
}).filter(Objects::nonNull)
.aggregateByKey(
new Tuple2<CovidVO, Integer>(new CovidVO(0D, 0D), 0),
(zeroValue, currentValue) -> {
CovidVO v = zeroValue._1;
v.setCases(v.getCases() + currentValue.getCases());
v.setDeaths(v.getDeaths() + currentValue.getDeaths());
return new Tuple2<>(v, zeroValue._2 + 1);
},
(p1, p2) -> {
CovidVO v1 = p1._1;
CovidVO v2 = p2._1;
v1.setCases(v1.getCases() + v2.getCases());
v1.setDeaths(v1.getDeaths() + v2.getDeaths());
return new Tuple2<>(v1, p1._2 + p2._2);
})
.map(t -> {
CovidVO v = t._2._1;
v.setCases(v.getCases() / t._2._2);
v.setDeaths(v.getDeaths() / t._2._2);
return new Tuple2<String, CovidVO>(t._1, v);
})
.sortBy(t -> t._2.deaths, false, 1)
.foreach(t -> {
System.out.println(t._1 + " " + t._2);
});
}
}
- Python:
from pyspark import SparkConf, SparkContext, StorageLevel
import findspark
if __name__ == '__main__':
findspark.init()
conf = SparkConf().setAppName('spark').setMaster('local[*]')
sc = SparkContext(conf=conf)
sc.setLogLevel("WARN")
t1 = sc.textFile("D:/test/input/")
def mapT(s):
line = s.split(",")
if (len(line) >= 6):
state = line[2]
casesStr = line[4]
deathsStr = line[5]
cases = float(casesStr if (casesStr and casesStr != '') else '0')
deaths = float(deathsStr if (deathsStr and deathsStr != '') else '0')
return (state, (cases, deaths))
else:
return None
t1.filter(lambda s: s and s != '') \
.map(mapT) \
.filter(lambda s: s != None) \
.aggregateByKey((0.0, 0.0, 0), lambda zeroValue, currentValue: (
zeroValue[0] + currentValue[0], zeroValue[1] + currentValue[1], zeroValue[2] + 1),
lambda p1, p2: (p1[0] + p2[0], p1[1] + p2[1], p1[2] + p2[2])) \
.map(lambda t: (t[0], t[1][0] / t[1][2], t[1][1] / t[1][2])) \
.sortBy(lambda t: t[2], ascending=False, numPartitions=1) \
.foreach(lambda t: print(t[0], t[1], t[2]))
统计结果:

. . .
相关推荐
热门推荐
动态扩容缩容的分库分表方案
200天前
SpringBoot前后端分离(Shir...
200天前
ostringstream 的用法
200天前
C.5 Paddlenlp之UIE关系抽...
199天前
dxf解析插件与dxf免费解析工具有哪些
196天前
CSS浮动布局分析与实现
196天前
【C++STL基础入门】stack栈的增...
196天前
Python嗅探socket
196天前
机器学习强基计划0-1:教程导读(附几十...
196天前
基于排队网络的电子商务系统的性能建模
193天前
最新推荐
Java开发中操作日志详解(InsCod...
201天前
特别练习-04 编程语言-03JAVA-...
200天前
在java中调用matlab程序时报错:...
200天前
渗透测试-apt攻击与防御系列-利用Wi...
196天前
elasticsearch 7.6.2 ...
196天前
C#的DateTimePicker控件(...
196天前
Cron 表达式一篇通
196天前
Java Exe生成工具 JSmooth
196天前
sigmoid & ReLU 等激活函数...
196天前
java当中的String算法和代码整洁...
196天前
ads via 小工具