参考文章:
深度剖析知识增强语义表示模型——ERNIE_财神Childe的博客-CSDN博客_ernie模型
https://github.com/PaddlePaddle/ERNIE/blob/develop/README.zh.md
1.背景介绍
近年来,语义表示(language representation)技术的发展,使得 “预训练-微调” 作为解决NLP任务的一种新的范式开始出现。一个通用的表示能力强的模型被选择为语义表示模型,在预训练阶段,用大量的语料和特定的任务训练该模型,使其编码海量的语义知识;在微调阶段,该模型会被加上不同的简单输出层用以解决下游的 NLP 任务。早期较为著名的语义表示模型包括ELMo 和 GPT ,分别基于双层双向LSTM和Transformer Decoder框架,而真正让语义表示技术大放异彩的是BERT (Bidirectional Encoder Representations from Transformers) 的提出。BERT以Transformer Encoder为骨架,以屏蔽语言模型 (Masked LM) 和下一句预测(Next Sentence Prediction)这两个无监督预测任务作为预训练任务,用英文Wikipedia和Book Corpus的混合语料进行训练得到预训练模型。结合简单的输出层,BERT提出伊始就在11个下游NLP任务上取得了 SOTA(State of the Art)结果,即效果最佳,其中包括了自然语言理解任务GLUE和阅读理解SQuAD。
可以看到,用语义表示模型解决特定的NLP任务是个相对简单的过程。因此,语义表示模型的预训练阶段就变得十分重要,具体来说,模型结构的选取、训练数据以及训练方法等要素都会直接影响下游任务的效果。当前的很多学术工作就是围绕预训练阶段而展开的,在BERT之后各种语义表示模型不断地被提了出来。
ERNIE(Enhanced Representation through kNowledge IntEgration)是百度提出的语义表示模型,同样基于Transformer Encoder,相较于BERT,其预训练过程利用了更丰富的语义知识和更多的语义任务,在多个NLP任务上取得了比BERT等模型更好的效果。
项目开源地址: https://github.com/PaddlePaddle/ERNIE
该项目包含了对预训练,以及常见下游 NLP 任务的支持,如分类、匹配、序列标注和阅读理解等。
2.原理介绍
2.1 Transformer Encoder
ERNIE 采用了 Transformer Encoder 作为其语义表示的骨架。Transformer 是由论文Attention is All You Need 首先提出的机器翻译模型,在效果上比传统的 RNN 机器翻译模型更加优秀。Transformer 的简要结构如图1所示,基于 Encoder-Decoder 框架, 其主要结构由 Attention(注意力) 机制构成:
- Encoder 由全同的多层堆叠而成,每一层又包含了两个子层:一个Self-Attention层和一个前馈神经网络。Self-Attention 层主要用来输入语料之间各个词之间的关系(例如搭配关系),其外在体现为词汇间的权重,此外还可以帮助模型学到句法、语法之类的依赖关系的能力。
- Decoder 也由全同的多层堆叠而成,每一层同样包含了两个子层。在 Encoder 和 Decoder 之间还有一个Encoder-Decoder Attention层。Encoder-Decoder Attention层的输入来自于两部分,一部分是Encoder的输出,它可以帮助解码器关注输入序列哪些位置值得关注。另一部分是 Decoder 已经解码出来的结果再次经过Decoder的Self-Attention层处理后的输出,它可以帮助解码器在解码时把已翻译的内容中值得关注的部分考虑进来。例如将“read a book”翻译成中文,我们把“book”之所以翻译成了“书”而没有翻译成“预定”就是因为前面Read这个读的动作。
在解码过程中 Decoder 每一个时间步都会输出一个实数向量,经过一个简单的全连接层后会映射到一个词典大小、被称作对数几率(logits)的向量,再经过 softmax 归一化之后得到当前时间步各个词出现的概率分布。
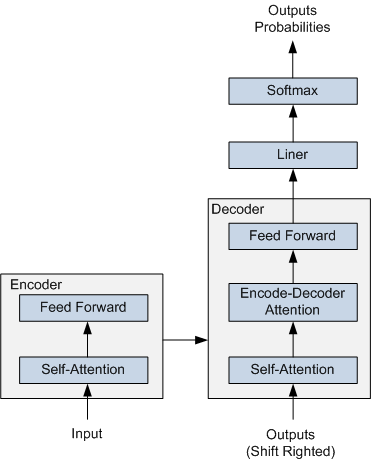
图 1 Transformer 的简要结构图
Transformer 在机器翻译任务上面证明了其超过 LSTM/GRU 的卓越表示能力。从 RNN 到 Transformer,模型的表示能力在不断的增强,语义表示模型的骨架也经历了这样的一个演变过程。如图2所示,该图为BERT、GPT 与 ELMo的结构示意图,可以看到 ELMo 使用的就是 LSTM 结构,接着 GPT 使用了 Transformer Decoder。进一步 BERT 采用了双向 Transformer Encoder,从理论上讲其相对于 Decoder 有着更强的语义表示能力,因为Encoder接受双向输入,可同时编码一个词的上下文信息。最后在NLP任务的实际应用中也证明了Encoder的有效性,因此ERNIE也采用了Transformer Encoder架构。
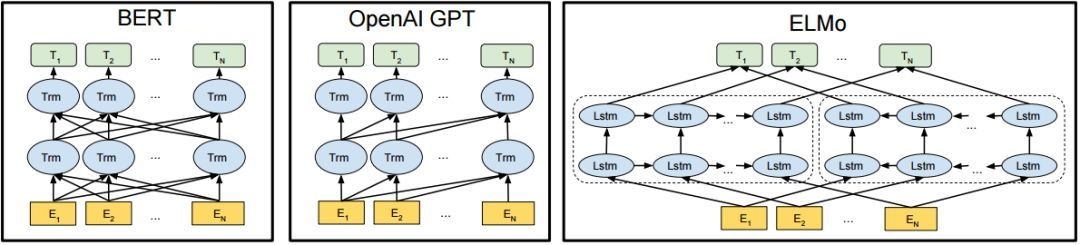
图2 BERT、GPT 与 ELMo
2.2 ERNIE
介绍了 ERNIE 的骨架结构后,下面再来介绍了 ERNIE 的原理。
ERNIE 分为 1.0 版和 2.0 版,其中ERNIE 1.0是通过建模海量数据中的词、实体及实体关系,学习真实世界的语义知识。相较于BERT学习原始语言信号,ERNIE 1.0 可以直接对先验语义知识单元进行建模,增强了模型语义表示能力。例如对于下面的例句:“哈尔滨是黑龙江的省会,国际冰雪文化名城”
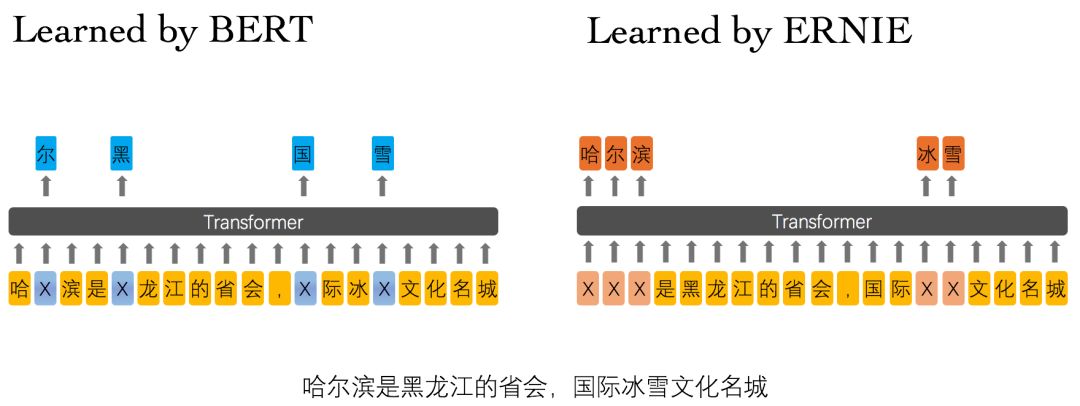
图3 ERNIE 1.0 与 BERT 词屏蔽方式的比较
BERT在预训练过程中使用的数据仅是对单个字符进行屏蔽,例如图3所示,训练Bert通过“哈”与“滨”的局部共现判断出“尔”字,但是模型其实并没有学习到与“哈尔滨”相关的知识,即只是学习到“哈尔滨”这个词,但是并不知道“哈尔滨”所代表的含义;而ERNIE在预训练时使用的数据是对整个词进行屏蔽,从而学习词与实体的表达,例如屏蔽“哈尔滨”与“冰雪”这样的词,使模型能够建模出“哈尔滨”与“黑龙江”的关系,学到“哈尔滨”是“黑龙江”的省会以及“哈尔滨”是个冰雪城市这样的含义。
训练数据方面,除百科类、资讯类中文语料外,ERNIE 1.0 还引入了论坛对话类数据,利用对话语言模式(DLM, Dialogue Language Model)建模Query-Response对话结构,将对话Pair对作为输入,引入Dialogue Embedding标识对话的角色,利用对话响应丢失(DRS, Dialogue Response Loss)学习对话的隐式关系,进一步提升模型的语义表示能力。
因为 ERNIE 1.0 对实体级知识的学习,使得它在语言推断任务上的效果更胜一筹。ERNIE 1.0 在中文任务上全面超过了 BERT 中文模型,包括分类、语义相似度、命名实体识别、问答匹配等任务,平均带来 1~2 个百分点的提升。
我们可以发现 ERNIE 1.0 与 BERT 相比只是学习任务 MLM 作了一些改进就可以取得不错的效果,那么如果使用更多较好的学习任务来训练模型,那是不是会取得更好的效果呢?因此 ERNIE 2.0 应运而生。ERNIE 2.0 是基于持续学习的语义理解预训练框架,使用多任务学习增量式构建预训练任务。如图4所示,在ERNIE 2.0中,大量的自然语言处理的语料可以被设计成各种类型的自然语言处理任务(Task),这些新构建的预训练类型任务(Pre-training Task)可以无缝的加入图中右侧的训练框架,从而持续让ERNIE 2.0模型进行语义理解学习,不断的提升模型效果。
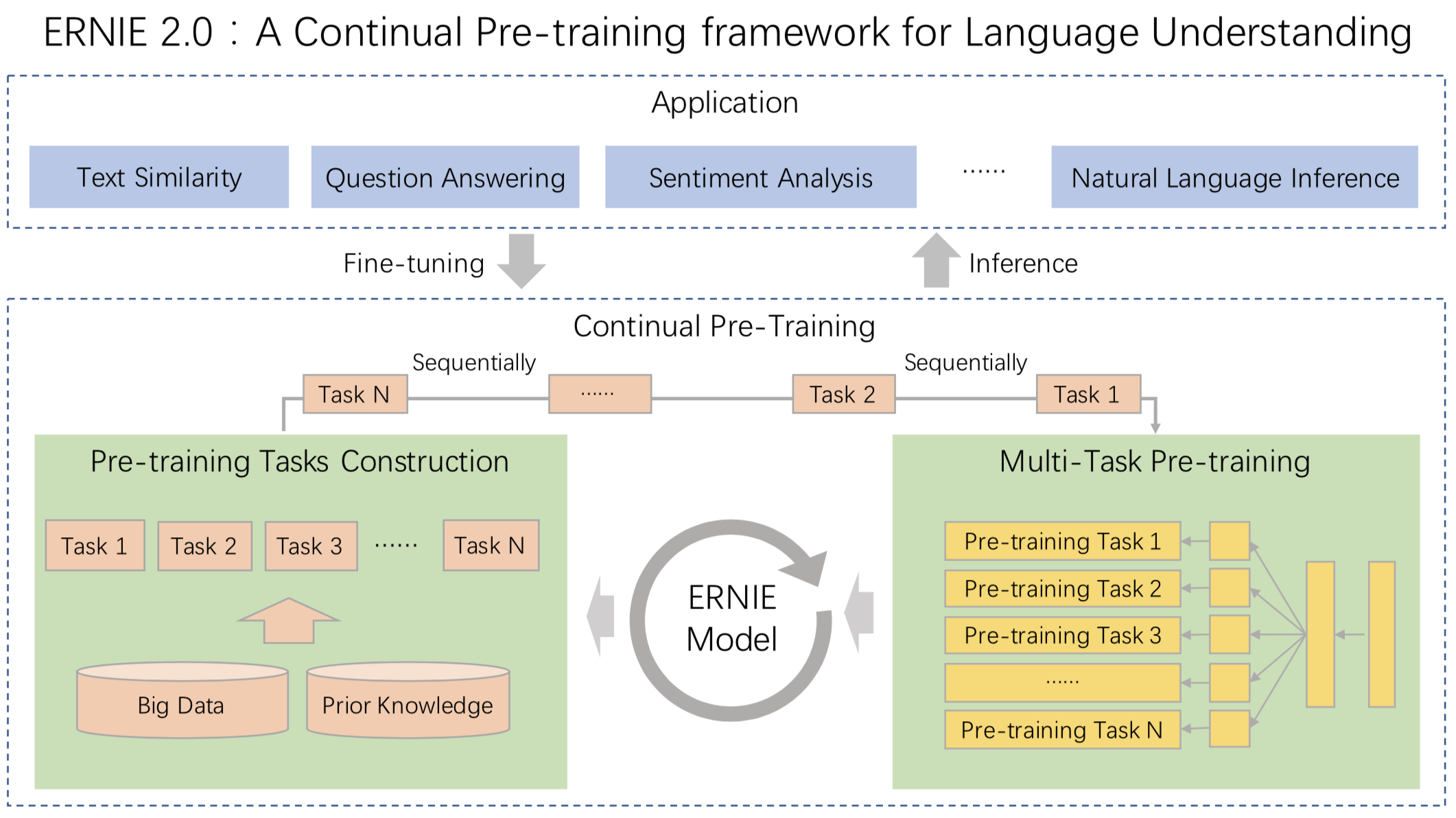
图4 ERNIE 2.0框架
ERNIE 2.0 的预训练包括了三大类学习任务,分别是:
- 词法层任务:学会对句子中的词汇进行预测。
- 语法层任务:学会将多个句子结构重建,重新排序。
- 语义层任务:学会判断句子之间的逻辑关系,例如因果关系、转折关系、并列关系等。
通过这些新增的语义任务,ERNIE 2.0语义理解预训练模型从训练数据中获取了词法、句法、语义等多个维度的自然语言信息,极大地增强了通用语义表示能力。ERNIE 2.0模型在英语任务上几乎全面优于BERT和XLNet,在7个GLUE任务上取得了最好的结果;中文任务上,ERNIE 2.0模型在所有9个中文NLP任务上全面优于BERT。
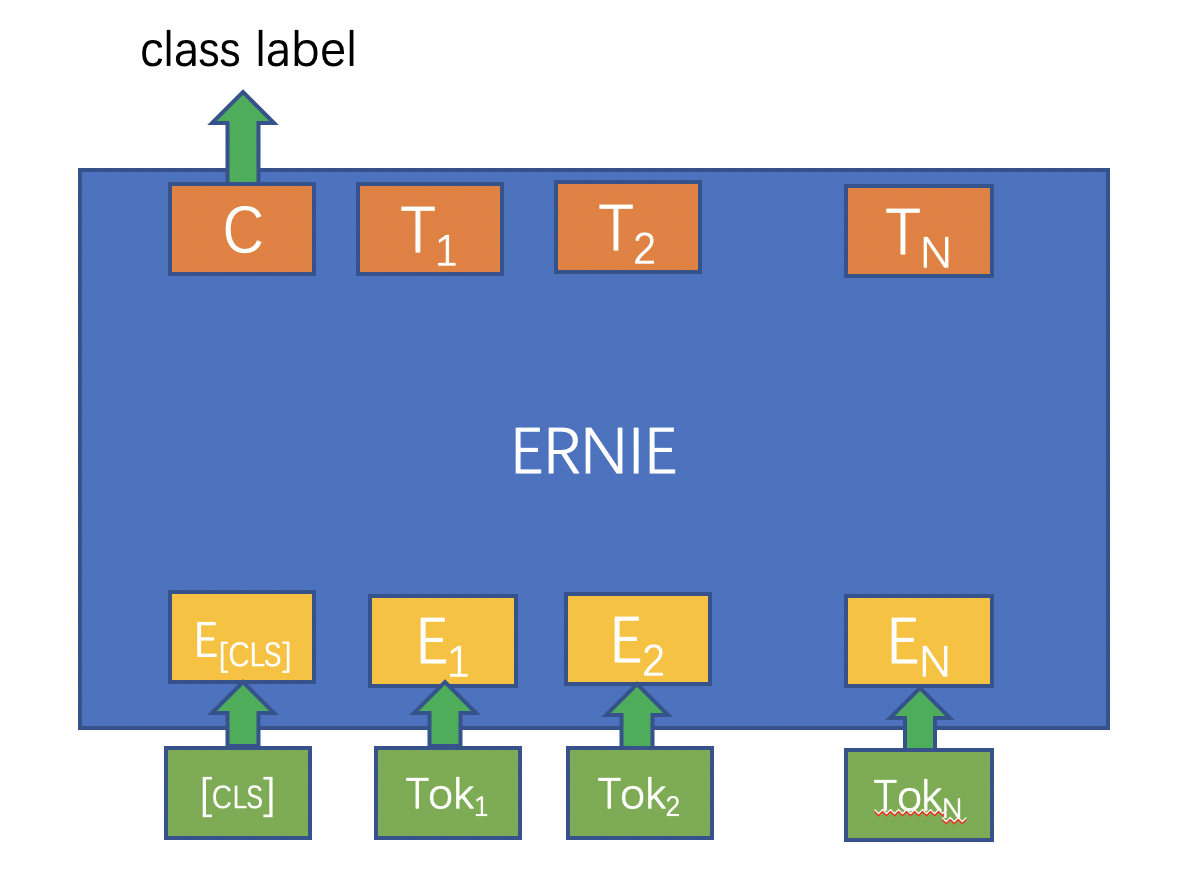
完成预训练后,如何用 ERNIE 来解决具体的 NLP 问题呢?下面以单句分类任务(如情感分析)为例,介绍下游 NLP 任务的解决过程:
- 基于tokenization.py脚本中的Tokenizer对输入的句子进行token化,即按字粒度对句子进行切分;
- 分类标志符号[CLS]与token化后的句子拼接在一起作为ERNIE模型的输入,经过 ERNIE 前向计算后得到每个token对应的embedding向量表示;
- 在单句分类任务中,[CLS]位置对应的嵌入式向量会用来作为分类特征。只需将[CLS]对应的embedding抽取出来,再经过一个全连接层得到分类的 logits 值,最后经过softmax归一化后与训练数据中的label一起计算交叉熵,就得到了优化的损失函数;
- 经过几轮的fine-tuning,就可以训练出解决具体任务的ERNIE模型。
关于ERNIE更详细的介绍,可以参考这两篇学术论文:
-
ERNIE: Enhanced Representation through Knowledge Integration
ERNIE 2.0: A Continual Pre-training Framework for Language Understanding
本教程不对预训练过程作过多展开,主要关注如何使用ERNIE解决下游的NLP任务。