
本报告的目的是查看真实数据,以更好地了解框架选择、性能和网络上实际用户体验之间的关系。我们将尝试阐明几个关键问题:
现代 Web 框架在实际使用和性能方面如何比较?
框架选择会影响网站的核心网络指标吗?
框架选择与 JavaScript 有效负载大小有何关系?它会产生什么影响?
数据
为此,我们研究了三个不同的公开数据集:
所有数据均来自独立管理的公共数据集。 Astro 团队尚未直接测量任何性能数据。在下面的部分中详细了解我们的方法。
框架
为了创建此报告,我们决定查看六个流行的基于 JavaScript 的 Web 框架: 阿斯特罗, 盖茨比, Next.js, 努克斯特, 混音和苗条套件.我们还包括来自WordPress的数据,由于其在网络上的受欢迎程度和巨大的市场份额(43.2%)。
由于我们选择的数据集中实际使用不足,必须排除几个令人兴奋的新框架,但我们希望在下一份报告中包含更多框架。
核心网络指标
Google 的核心网络指标 (CWV)是一组三个标准化指标,可帮助您了解用户体验网页的方式。每个指标衡量用户体验的不同方面——加载速度、响应能力、视觉稳定性——它们共同量化了网站的整体性能。
谷歌的核心网络指标评估是一个查看真实用户测量数据的测试(来自重要的数据集),以确定每个网站的总体通过/失败等级。要使网站通过,它必须满足相关阈值所有三个指标中的“良好”。如果任何指标未达到阈值,则网站无法通过评估。
CWV 评估的独特之处在于使用真实世界的用户数据和测量结果。这使得它能够更准确地反映用户实际体验网站的方式,尤其是在较长的会话中。 Lighthouse 和其他实验室测试工具只能测量主页负载,无法捕获网站的完整使用体验。
通过 CWV 的站点百分比

当查看使用特定框架构建的所有已知网站时,Astro 和 SvelteKit 击败了所有测试网站的平均通过率 (40.5%),而其余框架则不然。 Astro 是唯一一个超过 50% 的网站通过 Google CWV 评估的框架。接下来,.js Nuxt 分别通过了大约四分之一和五分之一的网站。
网站未通过 Google 核心网络指标评估的最可能原因是什么?我们可以按单个指标分解数据,以深入了解不同框架与网络指标的斗争(和成功)。
首次输入延迟 (FID)
通过 FID 的站点百分比

首次输入延迟 (FID)测量从用户首次与页面交互到浏览器能够响应该交互的时间。谷歌的CWV评估寻找100毫秒或更短的FID。任何较慢的东西都被认为是需要改进并且无法通过评估。
大多数框架都很容易通过这项测试,超过 90% 或更多的网站通过了评估。在这次测试中没有一个框架的通过率低于80%。这意味着大多数测试的网站都会响应第一次用户交互。
累积布局偏移量 (CLS)
通过 CLS 的站点百分比

累积布局偏移量 (CLS)测量页面上的视觉稳定性。若要通过此评估,应将意外的布局偏移减少到接近零,以便为用户提供可靠的视觉体验。
CLS 是 Google 的一个有趣的指标,作为三个核心网络指标之一,因为它与速度或响应能力并不严格相关。它的包含强调了在衡量网络用户体验的整体质量时不仅仅关注性能的重要性。
所有框架在此指标中的得分均为 50% 或更高。然而,最年轻的框架(Astro、SvelteKit 和 Remix)在此指标上得分最高。所有这三家公司在所有测试站点上的得分均超过 75%。
最大含量油漆 (LCP)
通过 LCP 的站点百分比
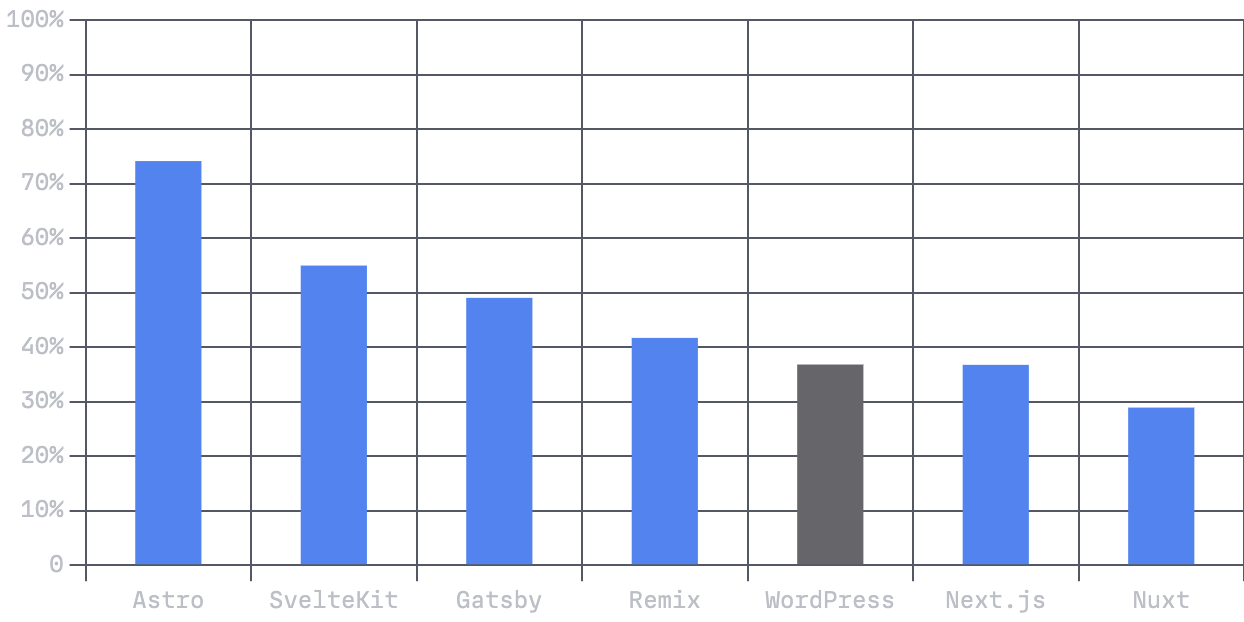
最大含量油漆 (LCP)是三个核心 Web 指标中的最后一个,在感知性能方面可以说是最重要的。它测量页面主要内容可能已加载的时间点。LCP 需要 2.5 秒或更短的时间才能通过谷歌的 CWV 评估。任何较慢的东西都被认为是需要改进并且无法通过评估。
LCP 是三个指标中最难掌握的。所有测试站点中只有 52% 通过了此指标。在我们测试的六个框架中,只有 Astro 和 SvelteKit 超过了这个平均值。其余均低于平均水平。
即将推出?与 Next Paint (INP) 的互动
Interaction to Next Draw (INP) 是一个实验性网络关键,用于评估网站的整体响应能力,类似于首次输入延迟 (FID)。这两个指标之间的区别在于,INP 会观察用户与页面的所有交互的延迟,而不仅仅是第一次。低 INP 意味着页面始终快速响应所有(或大多数)用户交互。
虽然INP在今天还不是至关重要的官方核心网络,但Chrome团队已经表表达他们的希望用INP取代FID,作为更全面,更准确的响应性衡量标准。
那么,这些框架如何与这个新的响应能力指标相比较呢?

图表中最值得注意的是,对于每个框架来说,良好的 INP 测量总体上比首次输入延迟 (FID) 更难实现。虽然每个测试的框架在 FID 上的通过率都超过 80%,但没有一个框架在 INP 上看到同样的 80% 通过率。 Astro最接近,通过率为68.8%。
值得注意的是,所有追踪网站的平均通过率高达60.9%。虽然 Astro 和 WordPress 在上图中看起来非常成功,但这些网站的实际表现仅略高于行业平均水平。为什么许多经过测试的 Web 框架很难使用这个指标?
原因之一可能是单页应用程序 (SPA) 架构通过 JavaScript 作为客户端操作驱动所有导航。这会产生输入滞后的机会,而没有客户端导航的多页应用程序 (MPA) 则不会出现这种情况。在 MPA 中,导航到新页面会触发服务器的完整页面加载,这不属于输入延迟。这可能有助于解释为什么 Astro 和 WordPress(图表中的两个 MPA)在此指标上的表现明显优于其他测试框架(所有 SPA)。
RebelMouse 的 Anne Burnes 有一篇关于 FID 和 INP 之间区别的精彩文章:
FID 量化了用户尝试与无响应页面交互时的体验,但它仅测量第一次交互。根据 Google 的说法,INP 通过涵盖网站上的整个交互范围(从页面首次加载时到用户离开页面时),更全面地衡量网站的响应能力。这种全面的测量使 INP 成为比 FID 更可靠的站点整体响应指标。
INP 的整体性使其比 FID 更具挑战性,因为您的代码的实现方式必须能够在整个过程中保护用户的响应能力,而不仅仅是在首次加载时。由于许多交互都是通过 JavaScript 完成的,这意味着您的网站必须小心加载以优化性能。
这在移动设备上尤其困难。我们查看了整个行业和站点网络中的少数站点,发现移动 INP 分数平均比 FID 差 35.5%。在同一数据集上查看桌面性能时,平均下降仅为 14.1%。
——安妮·伯恩斯,《叛逆的老鼠》
这将是 2023 年值得关注的一个有趣指标,因为谷歌继续考虑将 INP 添加为官方核心网络生活。
灯塔表演
灯塔是我们可以用来衡量网站用户体验的另一种工具。HTTP Archive 在模拟的移动加载条件下运行 Lighthouse。这提供了更详细和一致的页面加载性能分析,低至100毫秒的几分之一秒。Lighthouse 不会查看较大的“好”与“坏”阈值和存储桶,而是为您提供更详细的性能分数(满分 100 分)。

像核心页面指标这样的真实用户数据仍然是衡量真实用户体验的最佳指标,您可以在下面的一些图表中看到真实体验与实验室体验有何不同。然而,仍然可以从灯塔提供的额外细节中了解到有趣的见解。我们来看一下数据。
Lighthouse 性能得分,中位数
为了保持一致性,我们保留了上一节的原始顺序。但是,您会注意到 Remix 在灯塔上的表现似乎比在 CWV 评估中要强得多。对此的一种解释可能是 Remix 对 和startTransition requestIdleCallback页面加载延迟反应水化。从理论上讲,这可以转化为在某些实验室情况下(如Lighthouse)的更好性能,但代价是在其他现实世界中增加的第一输入延迟。
不幸的是,Beacon 的中值性能得分总体较低。一半的测试框架的中值性能被视为“差”(49 或以下),而另一半的中值分数为“需要改进”(50-89)。没有任何框架达到 90+ 的“良好”中值分数。

在所有跟踪的站点中,性能得分中位数为 34/100。为此,我们测试的一半框架(Astro、SvelteKit 和 Remix)确实高于互联网平均水平。
Lighthouse 性能得分,细分
通过按百分位数分解数据,我们可以开始看到一些稍微令人鼓舞的数字,Astro 和 SvelteKit 在 p90 或 p90 百分位数中取得了 95+ 的分数。然而,数据清楚地表明,所有网站和框架(包括 Astro)仍然难以在现实世界中实现良好的性能。
JavaScript 的成本
我们想要探索的最后一件事是框架选择、性能和实际使用中 JavaScript 有效负载总量之间的关系。最快的框架是否往往是向客户端发送最少数量的 JavaScript 的框架?

JavaScript KB 中位数与通过 CWV 的网站百分比
数据趋势很明显:发布较少 JavaScript 的网站往往表现更好。然而,有太多因素在起作用,我们无法自信地将这一趋势与 Web 框架本身的选择联系起来。某些框架可能以与其他框架不同的方式鼓励/阻止 JavaScript,但在我们得出任何结论之前还需要进行更多研究。
方法和限制
该报告根据多个公开数据集编制而成。您可以在此处了解有关这些数据集及其方法的更多信息:HTTP Archive Methodology、CrUX Methodology 和 CWV Technical Reporting Methodology。
由于容量限制,我们的分析仅查看了每个跟踪站点的主页。这一限制的好处之一是每个分析站点的目的和用例差异较小。然而,缺点是这也意味着内部页面(点赞和页面)及其使用的技术不会被分析,因此被排除在我们的分析之外。 /关于/管理/...
本报告中未探讨的另一个限制是框架的使用期限对测量的 Web 性能的影响。这里测量的旧框架(Gatsby、Next.js、Nuxt)具有较长的尾部,并且其运行的旧版本框架包含在数据集中。这就造成了一种情况,即只有较新的框架(Astro、Remix、SvelteKit)才能运行过去 1-2 年的更现代版本的软件。这是我们现有数据的局限性,但我们希望在未来的报告中探讨这一问题。