在网络中传递参数时,我们经常对参数进行Base64编码。那么Go语言中如何进行Base64编码呢? Base64编码的原理是什么?让我们通过这篇文章了解更多吧!
Go代码Base64编码(标准Base64编码、Base64 URL编码)
package main
import (
"encoding/base64"
"fmt"
)
func main() {
// 标准Base64编码
src := "hello world"
res :=base64.StdEncoding.EncodeToString([]byte(src))
fmt.Println(res) //aGVsbG8gd29ybGQ=
// 标准Base64解码
s, err :=base64.StdEncoding.DecodeString(res)
fmt.Println(string(s), err) //hello world
// Base64 URL 编码
src2 := "信息"
res2 :=base64.URLEncoding.EncodeToString([]byte(src2))
fmt.Println(res2) // 5L-h5oGv
// Base64 URL 解码
s2, err2 :=base64.URLEncoding.DecodeString(res2)
fmt.Println(string(s2), err2) // 信息 <nil>
}
什么是Base64编码
Base64 是互联网上传输 8Bit 字节码最常见的编码方法之一。它是一种基于 64 个可打印字符表示二进制数据的方法。 Base64编码是从二进制转换为字符的过程,可用于在HTTP环境中传递更长的标识信息。 Base64编码不可读,需要解码后才能读取。 -百度百科
通过百度百科的介绍,我们可以得到以下信息:
Base64是一种将二进制编码为字符的编码方法
Base64编码后的字符范围为64个可打印字符
编码结果不可读,需要解码:即Base64不是一种加密方法,而是一种编码方法,从一种语言翻译成另一种语言,当然也可以翻译回来
为什么需要Base64编码
我们都知道计算机世界是由0和1组成的,那么0和1的组合如何代表真正的语言呢?这就是 ASCII 代码出现的地方。 ASCII由美国设计,共有128个字符。它规定数字0~31和127(共33个)为控制字符或特殊通信字符,32~126(共95个)为可打印字符。例如,10(00001001)代表换行,65(0100 0001)代表大写字母A。
最初的许多协议都是基于 ASCII 设计的,只能传输可打印字符。比如发邮件时使用的 邮件传输协议(简单邮件传输协议),最初只能传输纯文本,对图片、语音等二进制文件的支持并不是太好。
那么如果我们要传输这些含有不可打印字符的数据该怎么办呢?一种方法是设计一种编码方法,将不可打印的字符转换为可打印的字符,从而可以传输数据。接收到数据后,解码回来,得到原始数据。 Base64就是为了解决这个问题而设计的。
目前的协议都是处理二进制文件,但我们不能保证文件在网络传输过程中不会出现问题。当包含不可打印字符的文件通过网络传输时,它们通常必须经过多个路由设备。由于不同的设备(尤其是老式的路由设备)处理字节流的方式不同,那些不可打印的字节可能会被错误地处理,不利于数据传输。因此,数据首先被编码并变成可见的字节,以保证数据的可靠传输。
Base64编码原理
Base64之所以称为Base64,是因为它是基于64个可打印字符设计的。这 64 个字符是 ASCII 编码中可打印字符的子集,包括 26 个大小写字母、10 个阿拉伯数字以及“+”和“/”符号。 (其实后缀还有‘=’号)
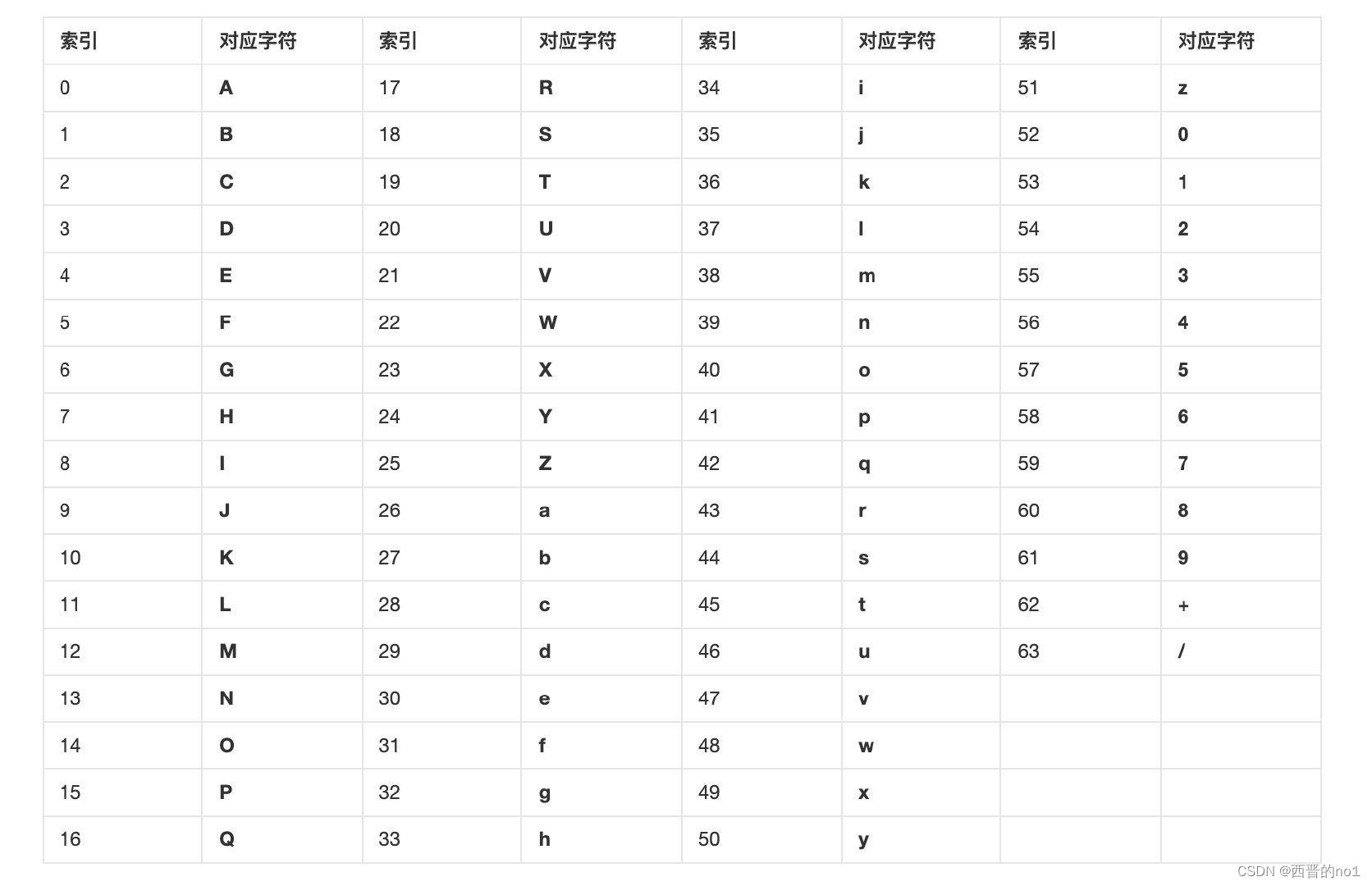
编码步骤
由于总共有64个字符,因此6位就足以表示它(2的6次方=64),而ASCII码使用8位来表示一个字符。 6和8的最小公倍数是24,3个ASCII字符可以编码成4个Base64字符。因此,Base64的编码过程如下:
将原始数据分为三个字节一组,共24位
将 24 位分为 4 组,每组 6 位
根据编码对照表计算每组的十进制值并得到可打印的字符串
我们用维基百科的例子来进行演示:
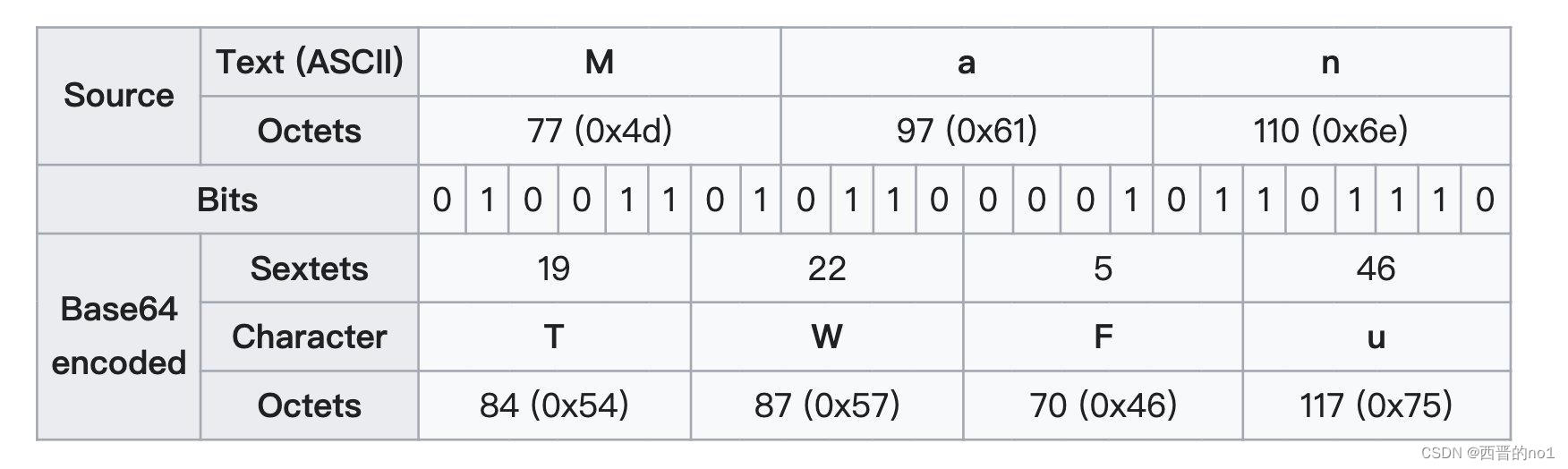
给定单词“Man”,有三个字节
根据ASCII编码,得到24位
6人为一组,分为4组
计算每组的十进制值为19、22、5、46,并与Base64编码表进行比较,得到可打印字符串为‘TWFu’
需要注意的是,使用Base64编码后,3个字节会转为4个字节,编码后需要传输的数据比编码前多了1/3。
数字不足
位数不足有两种情况:两个字节或一个字节数据。
如果是两个字节,即16位,则需要添加两个0,得到三个Base64编码字符,最后添加一个‘=’进行补充

如果是字节,即8位,则需要添加4个0,得到两个Base64编码字符,最后添加两个‘=’进行补充

Base64解码原理
解码是编码的逆操作:
删除末尾的“=”号
根据Base64编码表找到每个字符对应的编码值
取每个编码值的最后6位,形成一个二进制字符串
对于上面的二进制串,每8位组成一个字节。如果最后一组小于8,则必须全部为0并丢弃。
此时得到的是原始数据的二进制编码,然后根据编码方式(如ASCII)等进行解码。
例如,解码上面‘Ma’的编码值‘TWE=’:
删除“=”并得到“TWE”
‘T’:19,‘W’:22,‘E’:4
010011 010110 000100
01001101 01100001
嘛
Base64 标准编码变体
我们有时会在当前的HTTP URL中传递Base64编码的字符串和参数,但是标准的Base64不适合直接在URL中传输,因为使用url Encode时'+'符号会被编码。空格,比如,编码值为'ab+cd',但是使用urlencode后就变成了'ab cd',那么对方就会收到'ab cd',这时候解码肯定会失败。
为了解决这个问题,衍生出了一种改进的URL的Base64编码,不仅去掉了末尾的填充‘=’符号,还将标准Base64中的“+”和“/”改为“-”和“-”分别。 “_”。